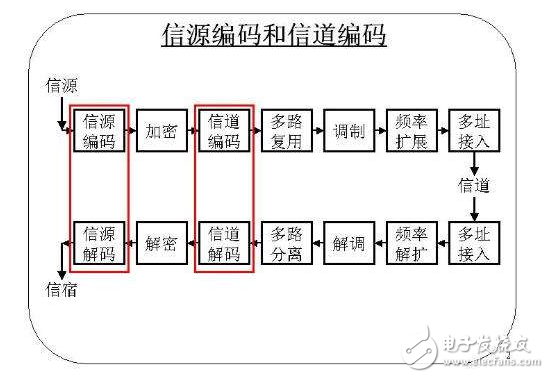
Source coding is a transformation of source symbols for the purpose of improving communication effectiveness, or in order to reduce or eliminate source margins. Specifically, it is to find a method according to the statistical characteristics of the signal source output symbol sequence to transform the signal source output symbol sequence into the shortest codeword sequence, so that the average amount of information carried by each symbol of the latter is the largest. The original symbol sequence can be guaranteed to be recovered without distortion. The purpose of source coding is to reduce or eliminate data redundancy. Under the premise of guaranteeing the quality of communication, to maximize the effect, through the compression of the source, so as to improve the effectiveness of communication. A method of transforming source symbols to reduce source redundancy. According to the nature of the source, there are known or unknown statistical characteristics of the source, no distortion or limited distortion, no memory or memory source coding; long code etc. The most common is discrete, stationary, distortion-free source coding with known source statistics. The main methods are: â‘ Statistical coding, such as Shannon code, Feino code, Huffman code, arithmetic code and so on. â‘¡ Predictive coding. â‘¢Transform coding, and a combination of the above methods (hybrid coding). The source code for which the statistical properties of the source are unknown is called a general code. The main indicator to measure the source coding is the compression ratio. In distortionless coding, the limit of compression is that the average code table of the code is equal to the symbol entropy of the source. In distortion-limited coding, the relationship between the compression limit of redundancy and the average distortion obeys the information rate-distortion R(D) function of the source. In engineering applications, a compromise is sought between compression ratio, average distortion and engineering implementation. During the transmission of digital signals, due to various reasons, bit errors are generated in the transmitted data stream, so that the receiving end produces image jumps, discontinuities, mosaics and other phenomena. Therefore, through the process of channel coding, the digital stream is processed accordingly, so that the system has certain error correction ability and anti-interference ability, which can greatly avoid the occurrence of bit errors in the transmission of the code stream. Error processing techniques include error correction, interleaving, and linear interpolation. It is the task of channel coding to improve the data transmission efficiency and reduce the bit error rate. The essence of channel coding is to increase the reliability of communication. However, channel coding will reduce the transmission of useful information data. The process of channel coding is to insert some symbols into the source data stream, so as to achieve the purpose of error judgment and error correction at the receiving end. This is the overhead we often say . This is just like when we ship a batch of glasses. In order to ensure that the glasses are not broken during transportation, we usually pack the glasses with some foam or sponge, which makes the glasses occupy the The volume of the glass has become larger. Originally, a car can hold 5,000 glasses, but after packaging, it can only hold 4,000 glasses. Obviously, the cost of packaging reduces the effective number of glasses for transportation. Similarly, in a channel with a fixed bandwidth, the total transmission code rate is also fixed. Since channel coding increases the amount of data, the result can only be at the expense of reducing the transmission rate of useful information. Dividing the number of useful bits by the total number of bits equals the coding efficiency. Different coding methods have different coding efficiencies. The Hierarchical Tree-based Set Partitioning (SPIHT) source coding method is an improved algorithm based on EZW. It effectively utilizes the multi-resolution characteristics of image wavelet decomposition and generates a bit stream according to the importance of a progressive coding. With this encoding method, the encoder can stop encoding at any position, so it can accurately achieve a certain target rate or target distortion. Likewise, for a given bitstream, the decoder can stop decoding at any point and still be able to recover the image encoded by the truncated bitstream. Achieving this superior performance does not require prior training and pre-stored tables or codebooks, nor does it require any prior knowledge about the image source. The error correction coding commonly used in digital TV usually adopts forward error correction (FEC) coding with two additional error correction codes. The RS code belongs to the first FEC, and the 16-byte RS code is appended to the 188 bytes to form the (204, 188) RS code, which can also be called outer coding. The FEC of the second additional error correction code generally adopts convolutional coding, also known as inner coding. The combination of outer coding and inner coding is called concatenated coding. The data stream obtained after concatenated encoding modulates the carrier frequency according to the prescribed modulation method. The codeword of the forward error correction code (FEC) is a code pattern with a certain error correction capability. After decoding at the receiving end, it can not only find the error, but also judge the position of the error symbol and automatically correct the error. This error correction code information does not need to be stored, does not need to be fed back, and has good real-time performance. Therefore, this channel coding method is used in broadcast systems (unidirectional transmission systems). The following are the various types of error correction codes: Since the basic purpose of source coding is to increase the average information content of the symbols in the codeword sequence, all transformations or processing performed on the source output symbol sequence to reduce the residual degree can be classified in this sense. Enter the category of source coding, such as filtering, prediction, domain transformation and data compression. Of course, these are generalized source codes. Generally speaking, there are two basic ways to reduce the residual degree in the output symbol sequence of the source and increase the average information content of the symbols: (1) Make each symbol in the sequence as independent as possible; (2) Make the occurrence probability of each symbol in the sequence as far as possible. possibly equal. The former is called discorrelation and the latter is called probability homogenization. The source coding in the third generation mobile communication includes voice compression coding, various image compression coding and multimedia data compression coding. The types of channel coding mainly include: linear block codes, convolutional codes, concatenated codes, Turbo codes and LDPC codes. The block code is further divided into: Hamming code, Gray code, cyclic code (BCH code, RS code, CRC cyclic redundancy check code. It is worth noting that: the Hamming distance between two code words in the binary code (or simply distance), is the number of different numbers in the codeword. For example: d(0, l) = l, d(001, 011) = 1, d(000, 111) = 3, d(111, 111) = 0 .
USB Flash Drives Compatible iPhone/iOS/Apple/iPad/Android & PC 128GB [3-in-1] Lightning OTG Jump Drive 3.0 USB Memory Stick
1. 3-in-1 OTG USB flash drive for PC, iPhone, Android, Type C
Iphone Ios Usb Flash Disk,Portable 2 In 1 , 3 in 1 Usb Pendrive,Otg Usb Flash Drives,Portable Otg Usb Flash Disk MICROBITS TECHNOLOGY LIMITED , https://www.hkmicrobits.com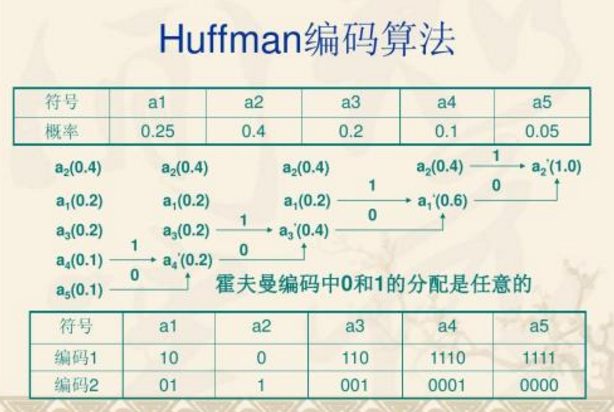
2. USB 3.0 + Android + IOS interface;
3. Capacity from 16~128GB;
4. Auto-run Function is optional;
5. Bootable Function;
6. Built-in Password Protection;
7. High speed Performance;
8. Data transfer rate for Read is from 12MB/s to 25MB/s, for Write is 4MB/s to 14MB/s in Dual-channel mode;
9. Data transfer rate for Read is from 8MB/s to 15MB/s, for Write is 2MB/s to 8MB/s in Single-channel mode;
(The rate of performance depends on the different operation system available and various flash adopted).
10. Operation Systems supported: No driver needed in Windows ME, Windows 2000, Windows XP, Mac 9.x or later, Linux Kernel 2.4 or later. Only Windows 98 and Windows 98SE need the enclosed driver;
11. 10 years data retention;
12. More than 1,000,000 times data encryption;
13. Built-in Password Protection is optional (default setting: NO password function);
14. Auto-run Function is optional (default setting: NO auto-run function);
15. Bootable Function is optional (default setting: NO bootable function);
16. ReadyBoost Function under Windows Vista system is optional (default setting: NO readyboost function).