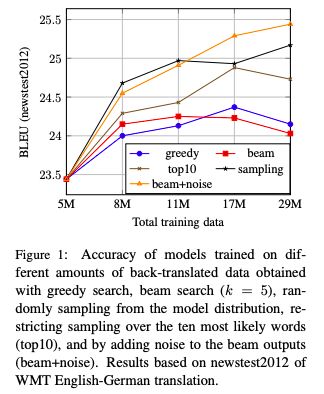
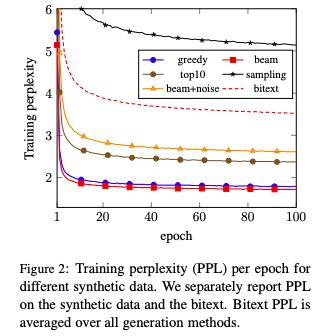
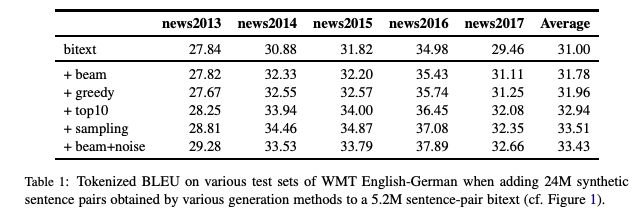
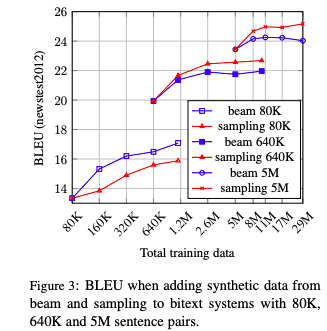
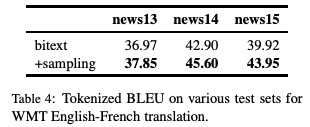
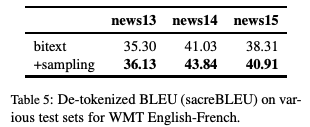
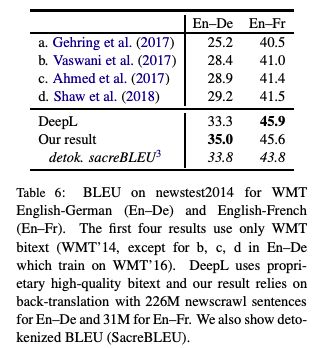
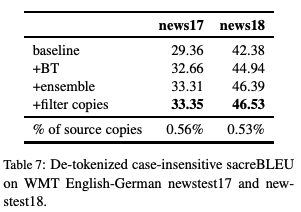
The collaborative research between FAIR and Google Brain, focusing on the "back translation" method, trains the NMT model with hundreds of millions of synthetic single sentence sentences, and achieves an optimal performance of 35 BLEU on the WMT'14 English-German test set. The paper was published at EMNLP 2018. Machine translation relies on large parallel corpora, i.e. datasets of paired sentences in source and target languages. However, bilingual corpus is very limited, and monolingual corpus is easier to obtain. Traditionally, monolingual corpora are used to train language models, which greatly improves the fluency of statistical machine translation. Progressing to the context of Neural Machine Translation (NMT) , there has been a great deal of work investigating how to improve monolingual models, including language model fusion , back -translation, and dual learning. These methods have different advantages and can be combined to achieve high accuracy. A new paper, Understanding Back-Translation at Scale , published by Facebook AI Research and Google Brain, is the latest on the subject. This paper focuses on back translation (BT), operating in a semi-supervised setting where both bilingual and monolingual data in the target language are available. Back-translation starts by training an intermediate system on parallel data, which is used to translate target monolingual data into the source language. The result is a parallel corpus where the source corpus is the synthetic machine translation output and the target corpus is real human-written text. The synthesized parallel corpus is then added to a real bilingual corpus (bitext) to train the final system that converts the source language to the target language. Although simple, this approach has been shown to be effective for phrase-based translation, NMT, and unsupervised MT. Specifically for this paper, the researchers conducted a large-scale study of the back-translation of neural machine translation by adding hundreds of millions of back-translated sentences to a bilingual corpus . The experiments are based on a strong baseline model trained on a public bilingual corpus of the WMT competition. This study expands on previous studies (Sennrich et al., 2016a; Poncelas et al., 2018) on back-translation methods to provide a comprehensive analysis of different approaches to generating synthetic source sentences and demonstrate that this choice matters : Sampling or noisy beam output from the model distribution outperforms pure beam search, with an average BLEU higher than 1.7 across several test sets. The authors' analysis shows that synthetic data based on sampling or noised beam search provides a stronger training signal than synthetic data based on argmax inference . The article also examines a comparison of adding synthetic data versus adding real bilingual data in a controlled setting, and surprisingly, the results show that synthetic data sometimes achieves accuracy comparable to real bilingual data. In the experiments, the best setting is on the WMT '14 English-German test set, reaching 35 BLEU , and the training data only uses the WMT bilingual corpus and 226 million synthesized monolingual sentences. This outperforms the DeepL system trained on a large premium dataset, improving by 1.7 BLEU . On the WMT '14 English-French test set, our system achieves 45.6 BLEU . Synthesized source sentence Back translation typically uses beam search or greed search to generate synthetic source sentences. Both algorithms are approximate algorithms that identify the output of a maximum a posteriori estimate (MAP) , i.e., the sentence with the highest probability of estimating given the input. Beam search usually succeeds in finding outputs with high probability. However, MAP prediction can lead to under-enriched translations, as it always tends to choose the most likely option in ambiguous cases. This is especially problematic in tasks with high uncertainty, such as dialogue and storytelling. We believe this is also problematic for data augmentation schemes such as back translation. Both beam search and greed search focus on the head of the model distribution, which leads to very regular synthetic source sentences that do not properly cover the true data distribution. As an alternative, we consider sampling from the model distribution and adding noise to the beam search output . Specifically, we transform the source sentence with three types of noise: removing words with probability 0.1, replacing words with padding symbols with probability 0.1, and swapping words randomly arranged on the token. Model and Experimental Results We reimplemented the Transformer model in pytorch using the fairseq toolkit. All experiments are based on the Big Transformer architecture, which has 6 blocks in both encoder and decoder. All experiments use the same hyperparameters. Experimental Results: Accuracy Comparison of Different Back-Translation Generation Methods The experimental evaluation first compares the accuracy of back-translation generation methods and analyzes the results. Figure 1: Accuracy of models trained on different amounts of back-translation data obtained by greedy search, beam search (k = 5), and random sampling. As shown in Figure 1, the sampling and beam+noise methods outperform the MAP method, and the BLEU is 0.8-1.1 higher. The sampling and beam+noise methods outperform bitext-only (5M) by 1.7-2 BLEU at the setting with the largest amount of data. Restricted sampling (top10) outperforms beam and greedy, but not as well as unrestricted sampling (sampling) or beam+noise. Figure 2: Training perplexity (PPL) per epoch for different synthetic data. Figure 2 shows that synthetic data based on greedy or beam are easier to fit than data from sampling, top10, beam+noise and bitext. Table 1 Table 1 presents the results on a wider test set (newstest2013-2017). Sampling and beam+noise perform roughly the same, and the rest of the experiments use sampling. Less resources vs more settings Next, we simulated a resource-starved setup to further experiment with different generation methods. Figure 3: Changes in BLEU when adding synthetic data from beam search and sampling in the bitext system of 80K, 640K and 5M sentence pairs Figure 3 shows that sampling is more efficient than beam for data-heavy settings (640K and 5.2M bittext), and the opposite is true for low-resource settings (80K bittext). large scale results Finally, we scale to very large settings, using up to 226M single-sentence sentences, and compare with previous studies. Table 4: Tokenized BLEU on different test sets in the WMT English-French translation task Table 5: De-tokenized BLEU (sacreBLEU) on different test sets in WMT English-French translation task Table 6: BLEU for WMT English-German (En-De) and English-French (En-Fr) on newstest2014. Table 7: Unmarked, case-insensitive sacreBLEU on WMT English-German newstest17 and newstest18. in conclusion Back translation is a very effective neural machine translation data augmentation technique. Generate synthetic source sentences by sampling or adding noise to the beam output with higher accuracy than the commonly used argmax inference. In particular, in the WMT English-German translation of newstest2013-2017, the sampled and noise-added beam performs an average of 1.7 BLEU better than the pure beam. Both methods provide richer training signals for resource-poor settings. In addition, this study found that models trained on synthetic data can achieve 83% of the performance of models trained on real bilingual corpora. Finally, we achieve a new state-of-the-art of 35 BLEU on the WMT '14 English-German test set using only publicly available benchmark data. USB C HUB,6 in 1 Type C Hub with Ethernet, 6 in 1 USB-C hub to HDMI,USB-C 6-in-1 Multiport Adapter,6 in 1 Multiport USB-C,USB-C Adapter Docking Hub Shenzhen Konchang Electronic Technology Co.,Ltd , https://www.konchang.com