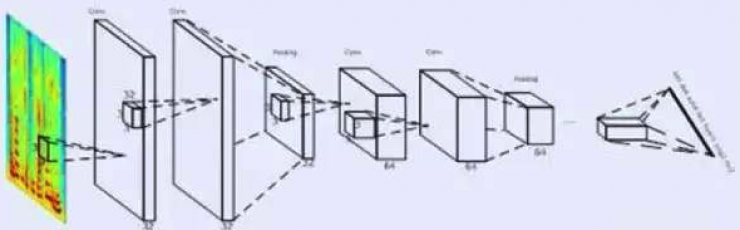
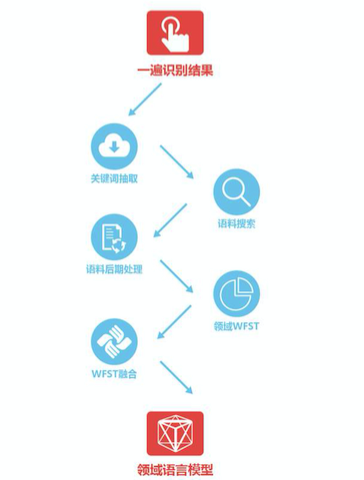
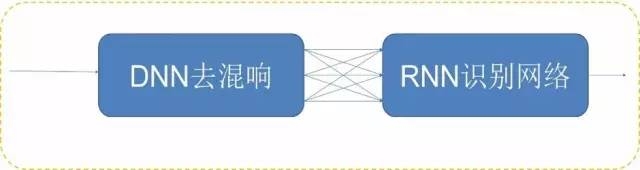
Introduction: At present, the best speech recognition system uses long-short-term memory (LSTM), but this system has the problems of high training complexity and high decoding delay, especially in real-time identification systems in the industrial world. It is difficult to apply. In this year, HKUST launched a new speech recognition framework called Deep Fully Convolutional Neural Network (DFCNN), which is more suitable for industrial applications. This article is a detailed explanation of the application of DFCNN to voice transcription technology used by HKUST News. It also includes the oral and textual language model processing for voice transcription, noise and far-field recognition, and real-time correction of text processing and text. Processing and other technical analysis. In the application of artificial intelligence, speech recognition has made significant progress this year. Whether it is English, Chinese or other languages, the accuracy of machine speech recognition is constantly rising. Among them, the development of voice dictation technology is the fastest, and it has been widely used in voice input, voice search, voice assistant and other products and is now mature. However, there is still a certain difficulty in another aspect of voice application, namely voice transcription. Since the user does not expect the recording to be used for speech recognition in the process of generating a recording file, it is compared with speech dictation. Voice transcription will face many challenges such as speaking style, accent, and recording quality. Typical scenarios for voice transcription include interviews with reporters, television programs, classes, and conversational meetings, and even any recordings made by anyone in their daily work life. The market for voice transcription and imagination are huge. Imagine that if humans can conquer voice transcription, TV programs can automatically and vividly subtitle, formal meetings can automatically form notes, and reporters' recordings can be automatically written.... The words spoken in life are much more than words we have written. If there is a software that can record all the words we have said and conduct efficient management, the world will be incredibly unbelievable. Acoustic modeling of speech recognition is mainly used to model the relationship between speech signals and phonemes. On December 21 last year , HKUST launched a feed-forward Sequential Memory Network (FSMN) as acoustic modeling. After the framework, this year again introduced a new speech recognition framework, Deep Fully Convolutional Neural Network (DFCNN) . At present, the best speech recognition system adopts Long Short Term Memory (LSTM), which can model the long-term correlation of speech and improve the recognition accuracy. However, the bidirectional LSTM network has the problems of high training complexity and high decoding delay, especially in real-time identification systems in the industry. Therefore, HKUST adopts a deep full-sequence convolutional neural network to overcome the defects of the bidirectional LSTM. CNN was used in speech recognition systems as early as 2012, but there has been no major breakthrough. The main reason is that it uses fixed-length frame splices as input and cannot see long enough voice context information; another flaw treats CNN as a feature extractor, so the number of convolutional layers used is limited and its expressive power is limited. . To address these issues, DFCNN uses a large number of convolutional layers to model the entire sentence speech signal directly. First of all, the input of DPCNN directly takes the gen- odogram as input, which has a natural advantage over other speech recognition frameworks that use traditional speech features as input. Secondly, in the model structure, the network configuration of image recognition is used, small convolution kernels are used in each convolution layer, and pooled layers are added after multiple convolution layers, and a large number of convolution pools are accumulated. The pair is right, so you can see very long history and future information. These two points guarantee that the DFCNN can express the long-term correlation of speech well. Compared with the RNN network structure, it is more robust in terms of robustness. At the same time, it can realize short-delay quasi-online decoding and can be used in industrial systems. (DFCNN structure diagram) The speech recognition language model is mainly used to model the correspondence between phonemes and words. Since human speech is an unstructured natural language, people often hesitate, read back, modal words and other complex linguistic phenomena when they are free to talk. The textual material is usually written language. The chasm creates great challenges for the modeling of language models for spoken languages. HKUST adopts the idea of ​​noise-enhancement training to deal with noise in speech recognition processing, that is, it automatically introduces the “noise†spoken language such as reading back, flip-up, and modal words on the basis of written language, which can automatically generate massive spoken language corpora and solve spoken language. Mismatches between written and written language. Firstly, some colloquial and written corpus pairs are collected; secondly, the correspondence between written and spoken texts is modeled using a neural network framework based on Encoder-Decoder, so as to realize automatic generation of spoken texts. In addition, contextual information can help humans to understand the language to a greater extent, and the same applies to machine transcription. Therefore, HKUST News proposed a chapter-level language model on December 21 last year. The program automatically extracts key information based on the decoding results of speech recognition, performs corpus search and post-processing in real time, and uses decoding results and searched corpora to form Specific speech-related language models to further improve the accuracy of speech transcription. (Text model language flow chart) The application of speech recognition far-field pickup and noise interference have been two major technical problems. For example, in a conference scenario, if a recording pen is used for recording, the speaker's voice far from the recording pen is a far-field with reverberation speech. Since the reverberation will cause unsynchronized speech to be superimposed on each other, the phoneme will be brought in. Overlapping masking effects, which seriously affect the effect of speech recognition; Similarly, if there is background noise in the recording environment, the voice spectrum will be contaminated, and its recognition effect will drop sharply. HKUST has used the single-microphone and microphone arrays for noise reduction and de-reverberation technologies in this hardware environment. This has enabled voice transfer in far-field and noise environments to reach a practical threshold. Single microphone noise reduction, reverberation For the collected lossy speech, mixed training and decombination-reverberation combining method based on depth regression neural network are used. That is, on the one hand, noise is added to clean speech and mixed training is performed together with clean speech, thereby improving the robustness of the model to noisy speech (Editor's note: Robust's transliteration, ie, robust and strong meaning); on the other hand, The use of a depth-regressive neural network for noise reduction and dereverberation further improves the recognition accuracy of noisy and far-field speech. Microphone array noise reduction, reverberation Simply considering the noise in the process of voice processing can be said to be a temporary solution. How to solve reverberation and noise reduction at the source seems to be the key to the problem. Faced with this problem, HKUST’s R&D personnel used multi-microphone arrays to perform noise reduction and de-reverberation by adding multiple microphone arrays to recording equipment. Specifically, multiple time-frequency signals are collected using multiple microphones, and beamforming is learned using a convolutional neural network, thereby forming a picked-up beam in the direction of the target signal and attenuating the reflected sound from other directions. The combination of the method and the above-described single-microphone noise reduction and reverberation can further significantly improve the recognition accuracy of the noisy and far-field speech. All of the above are just the processing techniques for speech, that is, the transcription of the recording into text, but just as the above-mentioned human speech is an unstructured natural language, even if the speech transcription accuracy rate is very high, the speech is transferred. There is still a big problem with the readability of written texts, so the importance of text post-processing is reflected. The so-called textual post-processing is to parse and segment the colloquialized texts, process the fluency of the textual content, and even summarize the content so as to facilitate better reading and editing. Post-processing I: clauses and segments The clauses are divided into clauses according to the semantics of the transposed text, and punctuation is added between the clauses; the segmentation, that is, the text is divided into several semantic paragraphs, and the subtopics described in each paragraph are different. By extracting context-related semantic features and combining speech features, clauses and paragraphs are divided; taking into account that marked voice data is more difficult to obtain, in practical applications, HKUST utilizes two-stage cascaded bidirectional long-short memory networks. Modular technology, so as to better solve the problem of segmentation and segmentation. Post-processing II: smooth content Smooth content, also known as not smooth detection, is to eliminate stop words, modal words, repeated words in the transfer result, and make smooth text easier to read. With the use of generalization features and the combination of two-dimensional long-term and short-term memory network modeling technologies, HKUST has achieved a smooth and accurate content rate for the practical stage. Source: HKUST News Public Modern Physics Experiment Series Modern physics experiment related equipment for efficient specialized physics laboratory Modern Physics Experiment Instruments,Optical Instruments,Acousto-Optic Modulator Experimental Device,Optical Spectroscopy Experiment Determinator Yuheng Optics Co., Ltd.(Changchun) , https://www.yhenoptics.com