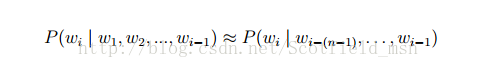〇, Preface Some time ago, NLP was combined with deep learning to consider some issues. One of the problems was considered to be the core one: After all, how did the in-depth network work to make the various NLP missions perfect? What exactly does my data send in NN? And, a lot of terms like: word vectors, word embedding, distributed representation, word2vec, glove, and so on. What does this porridge noun term stand for, what is their specific relationship, and are they in a flat relationship? Because of the old problems of obsessive-compulsive disorder that are pursuing a complete understanding of the knowledge structure, they constantly search for information, think, and keep revolving... Then I felt a little progress. If you think of it, it's better to understand it personally. Whether it's right or wrong, if you share it with a peer first, maybe you can exchange more meaningful things? The structure of the entire article is based on the logic of the concept of the size of the sequence, layer by layer, one level down to analyze, compare and explain. In addition, the entire text here is relatively introductory, and even some of the points may be less accurate and objective. It is limited to the current cognitive level... Please also Haihan, I hope you correct me in the comments! First, the core key of DeepNLP: Representation There is a new term recently: Deep Learning + NLP = DeepNLP. When the conventional machine learning machine learning upgrade developed to a certain stage, it was gradually taken away from deep learning Deep Learning away and led a wave of new climax in full swing, because Deep Learning has machinelearning over and over Department! When Deep Learning enters the NLP field, it is natural to sweep through a batch of ACL papers. The same is true. First mention the data features to represent the problem. Data representation is the core issue of machine learning. In the past Machine Learning phase, a large number of feature projects were created, and a large number of features were manually designed to solve the problem of effective data representation. When you come to Deep Learning, don't even think about it. End-2-end, in one step, hyper-parameter automatically help you choose the key feature parameters. So, how can Deep Learning play its due real power in NLP? Obviously, not to mention how to design a very strong network structure, not to mention how to introduce NN-based solutions such as sentiment analysis, entity recognition, machine translation, and text generation in the NLP, we must first express the language. Turned off - how to make the language representation a data type that the NN can handle. Let's take a look at how images and speech represent data: In speech, a matrix made up of audio frequency spectrum sequence vectors is used as the front-end input and fed to the NN for processing. In the image, the vector formed by the pixels of the picture pixels is flattened into a vector and fed to the NN for processing. What about natural language processing? You may or may not know that each word is represented by a vector! The idea is quite simple, yes, it is actually so simple, but is it really that simple? It may not be so simple. It was mentioned that images and voices are naturally low-level data representations. In the field of image and speech, the most basic data is signal data. We can use some distance metrics to judge whether signals are similar or not. When judging whether two images are similar, You can give an answer simply by looking at the picture itself. Language, as a tool for mankind's evolution of the high-level abstract thinking information expressed by millions of years of evolution, has a highly abstract feature. Text is symbol data. It is difficult for two words to describe them as long as they are literally different. Even though it is synonymous with "microphone" and "microphone", it is difficult to see that the two have the same meaning (semantic gap), which may not be simply expressed in one simple plus one. When judging whether two words are similar, more background knowledge is needed to answer them. According to the above, is it possible to confidently conclude a conclusion: how to effectively express language sentences is the key precondition for determining the ability of NN to exert a strong fit for computing! Second, NLP word representation method type Next, according to the above ideas, the expression of various words will be drawn. According to today's current development, the expression of words is divided into one-hot, one-hot, and distributed-distributed. 1. One-hot representation of words The most intuitive and most commonly used word representation method in NLP is the One-hot Representation. This method represents each word as a very long vector. The dimension of this vector is the size of the vocabulary, where most of the elements are 0 and only one dimension has a value of 1, which represents the current word. There is a lot of information about one-hot coding, street goods, here is a brief description of the chestnut: "Microphone" is represented as [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 ...] "Mike" is represented as [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 .. .] Each word is a 1 in the sea. This One-hot Representation is very concise if it is stored sparsely: that is, assign a numeric ID to each word. For example, in the previous example, the microphone is recorded as 3, and the microphone as 8 (assuming that it starts from 0). If you want to programmatically implement it, use the Hash table to assign a number to each word. Such a simple representation method, together with algorithms such as maximum entropy, SVM, CRF, etc., has successfully completed various mainstream tasks in the NLP field. Now we analyze his misconduct. 1. The dimension of a vector increases with the number of words in the sentence. 2. Any two words are isolated and cannot represent the relevant information between the words at the semantic level. This is deadly. 2. The distributed representation of words The traditional one-hot representation merely symbolizes words and does not contain any semantic information. How to integrate semantics into word representation? The distributional hypothesis proposed by Harris in 1954 provided the theoretical basis for this idea: contextual similar words whose semantics are similar. Firth further elaborated and clarified the distribution hypothesis in 1957: The semantics of the word are determined by its context (a word is characterized by the company it keeps). So far, the word representation based on distribution hypothesis can be divided into three categories according to different modeling: matrix-based distribution representation, cluster-based distribution representation, and neural network-based distribution representation. Although these different distribution representation methods use different technical means to obtain word representations, because these methods are all based on the distribution hypothesis, their core ideas are also composed of two parts: First, choose a way to describe the context; Second, choose one A model characterizes the relationship between a word (hereinafter referred to as "target word") and its context. Third, NLP language model Before describing the distributed representation of a word in detail, it is necessary to describe a key concept in the NLP: the language model. Language models include grammar language models and statistical language models. Generally we refer to statistical language models. The reason why the language model is placed before the word representation method is because the latter expression method will use this concept immediately. Statistical language model: The statistical language model treats a language (a sequence of words) as a random event and assigns corresponding probabilities to describe its possibility of belonging to a certain set of languages. Given a vocabulary set V, for a sequence consisting of words in V S = 〈w1, ···, wT〉 ∈ Vn, the statistical language model assigns this sequence a probability P(S) to measure S in accordance with natural language Confidence in grammar and semantic rules. In a nutshell, the language model is the model for calculating the probability of a sentence. What's the point? The higher the probability of scoring a sentence, the more he explains that he is a more natural sentence. It's that simple. Common statistical language models are N-gram models, the most common of which are unigram models, bigram models, trigram models, and so on. Formally speaking, the role of the statistical language model is to determine a probability distribution P(w1; w2; :::; wm) for a string of length m, indicating the possibility of its existence, where w1 to wm in turn represent this paragraph Each word in the text. In the actual solution process, the following formula is usually used to calculate the probability value: At the same time, through these methods, it is also possible to retain a certain word order information, so that the context information of a word can be captured. The details of the specific language model are street goods. Please search on the details yourself. Fourth, the word's distributed representation 1. Matrix-based distribution representation A matrix-based distribution representation is also commonly referred to as a distribution semantic model. Under this representation, a row in a matrix becomes a representation of a corresponding word, which describes the distribution of the context of the word. Because the distribution hypothesis considers words with similar contexts and their semantics are similar, the semantic similarity of two words can be directly translated into the spatial distance of two vectors under this representation. The common Global Vector model (GloVe model) is a method of decomposing the word-word matrix to obtain the word representation, which belongs to the matrix-based distribution representation. 2. Cluster-based distribution representation The distribution based on clustering indicates that I am not too clear, so I will not describe it in detail. 3. Based on the distribution of neural networks, word embedding Neural network-based distribution representations are generally referred to as word vectors, word embeddings, or distributed representations. This is our main character today. Neural network word vector representation technology uses neural network technology to model the context, and the relationship between context and target words. Since neural networks are more flexible, the greatest advantage of this type of approach is that they can represent complex contexts. In the previous matrix-based distribution representation, the most common context is the word. If you use an n-gram containing word order information as the context, the number of n-grams grows exponentially as n increases and you experience dimension disasters. When the neural network expresses n-grams, n words can be combined by some combinations. The number of parameters only grows at a linear speed. With this advantage, neural network models can model more complex contexts and contain richer semantic information in word vectors. Fifth, word embedding (word embedding) 1, concept Neural network-based distribution representation is also called word vector and word embedding. Neural network word vector model, like other distribution representation methods, is based on the distribution hypothesis. The core is still the expression of context and the modeling of the relationship between context and target words. . As mentioned earlier, in order to select a model to characterize the relationship between a word (hereinafter referred to as “target wordâ€) and its context, we need to capture the context information of a word in the word vector. At the same time, we just mentioned that the statistical language model has the ability to capture contextual information. The most natural way to build the relationship between context and target words is to use language models. Historically, early word vectors were only by-products of neural network language models. In 2001, Bengio et al. formally proposed the Neural Network Language Model (NNLM), which learned the language model and also obtained word vectors. Therefore, please note that the word vector can be considered as a byproduct of the neural network training language model. 2, understand As mentioned earlier, the one-hot notation has the disadvantage of being too large in dimension. Now we will make some improvements to the vector: 1. Change each element of the vector from a plastic to a floating-point type and change it into a representation of the entire real number range; The original, sparse, huge dimension of compression is embedded into a smaller dimension of space. As shown: This is also the reason for the word vector and noun embedding. VI. Neural network language model and word2vec Well, so far we have a rational understanding of the hierarchical relationship between the concept of distributed representation and the concept of word embedding. So what does this have to do with word2vec? 1, neural network language model As mentioned above, the word vector can be obtained through a neural network training language model. Then, what types of neural network language models are there? As individuals know, there are roughly these: a) Neural Network Language Model ,NNLM b) Log-Bilinear Language Model, LBL c) Recurrent Neural Network based Language Model, RNNLM d) The C&W model proposed by Collobert and Weston in 2008 e) Mikolov et al. proposed CBOW (continuous Bagof-Words) and Skip-gram models. At this point, it is estimated that someone has seen two familiar terms: CBOW, skip-gram, and students who have seen word2vec should understand this. We continue. 2.word2vec with CBOW, Skip-gram Now we formally elicit another hottest term: word2vec. The five neural network language models mentioned above are just logical concepts. Then we have to implement them through design. The tools to implement the CBOW (Continuous Bagof-Words) and Skip-gram language models are exactly Well-known word2vec! In addition, the implementation tool for the C&W model is SENNA. So, the distributed word vector was not invented by the author of word2vec, he just proposed a faster and better way to train the language model. These are the Continous Bag of Words Model (CBOW) and the Skip-Gram Model. These two methods are methods that can train the word vectors. You can choose only one of the specific code operations, but according to the paper, CBOW Be faster. By the way, these two language models. The statistical language model is to give you several words, and to calculate the probability of (after) occurrence of a certain word. CBOW is also a kind of statistical language model. As its name implies, it calculates the probability of occurrence of a word based on C words in front of a word or C continuous words before and after. The Skip-Gram Model, on the other hand, is based on a word and then computes the respective probabilities for certain words before and after it. Take the phrase “I love Beijing Tiananmen†as an example. Let's suppose that the word we are now concerned with is "love," and when C = 2, its context is "I" and "Beijing Tiananmen." The CBOW model uses the one-hot representation of "I" and "Beijing Tiananmen" as input, that is, C 1xV vectors, which are respectively multiplied by the coefficient matrix W1 of the same VxN size to obtain C 1xN hidden layers hidden layers. Then C is averaged so only a hidden layer is counted. This process is also known as a linear activation function (this is also the activation function? It is clear that there is no activation function). Then it is multiplied with another NxV-size coefficient matrix W2 to get a 1xV output layer. Each element of this output layer represents the post-event probability of each word in the thesaurus. The output layer needs to be compared with ground truth, which is the "love" one hot form. It should be noted here that V is usually a very large number, such as several million. It is computationally time-consuming, except that the element that "loves" that position must be counted in loss, and word2vec is filtered out using the Hierarchical softmax based on the huffman code. Some of the impossible words, and then use nagetive samping to remove some of the negative samples so the time complexity from O (V) to O (logV). Skip gram training process is similar, but the input and output are just the opposite. In addition, Word embedding training methods can be roughly divided into two categories: one is unsupervised or weakly supervised pre-training; the other is end-to-end supervised training. Unsupervised or weakly supervised pretraining is represented by word2vec and auto-encoder. The feature of this type of model is that it can get a good quality embedding vector without a large amount of artificial marker samples. However, because of the lack of task orientation, there may be a certain distance from the problem we are trying to solve. Therefore, we often use a small amount of manually annotated sample to get the fine-tune whole model after getting the pre-trained embedding vector. In contrast, the end-to-end supervised model has received increasing attention in recent years. End-to-end models tend to be more complex in structure than unsupervised models. At the same time, because of the clear task orientation, the embedding vector learned by the end-to-end model is often more accurate. For example, a deep neural network formed by concatenating an embedding layer and a plurality of convolutional layers is used to realize the emotional classification of sentences, and a more semantically rich word vector expression can be learned. 3. Personal understanding of word embedding Now, the word vector can not only reduce the dimension, but also can capture the context information of the current word in the sentence (represented as the context distance relationship). Then we are very confident and satisfied with the input of the language sentence word as NN. . Another very practical suggestion, if you want to use a word vector when doing a specific NLP task, then I suggest you: either 1. Choose to use someone else's trained word vector, pay attention, use the same language content Words in the domain; 2 or 2. Train your own word vector. My suggestion is the former because ... there are too many pits. Seven words Having said this, in fact, I didn't intend to continue with the plan, that is, I did not intend to talk about word2vec's mathematical principles and detailed explanations, because I found that there are too many articles about the word2vec on the Internet. , to almost all articles are the same. So I don't need to copy another copy. So, to learn more about the details of word2vec, cbow, skip-gram, please search carefully. I believe that in the context of understanding the context of this series of prerequisites, you will certainly not find it difficult to read the detailed articles related to word2vec. In addition, this also reflects a bigger problem, that is, online articles lack the originality of critical thinking. Searching “word2vec†and “word vector†casually on the Internet, then a lot of explanations on the mathematical formulas of word2vec, cbow, skip-gram, and everything are the same... But the most unappreciable is that basic There is no one to mention in detail these things his context of his presence, the process of his development, his place in the entire relevant technical framework, and so on. This makes me very depressed... In fact, by the way, in my personal methodological thinking, a knowledge framework with a complete context and a well-structured structure is, to a certain extent, more important than some detailed knowledge points! Because once a complete knowledge structure framework is constructed, all that you have to do is to fill in pieces of bits and pieces; but in reverse it will not work at all. Knowledge stacking will only make you confused and unable to walk. How far. So here I also appeal to bloggers, everyone can give full play to their initiative, take the initiative to create something that is not, share some unique insights, it can also be regarded as the contribution to the Chinese network blog and the CS cause! I mean, even if copying someone's original thing, it is best to chew, chewing, add their own things after digestion and share it! Product categories of Maskking, we are specialized electronic cigarette manufacturers from China, Vapes For Smoking, Vape Pen Kits, E-Cigarette suppliers/factory, wholesale high-quality products of Modern E-Cigarette R & D and manufacturing, we have the perfect after-sales service and technical support. Look forward to your cooperation! maskking e cigarette, maskking vape pen, maskking disposable vape, Maskking HIGH GT Vape, maskking vape Ningbo Autrends International Trade Co.,Ltd. , https://www.mosvape.com