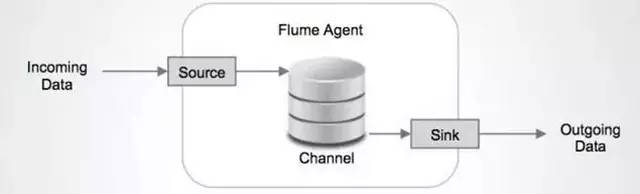
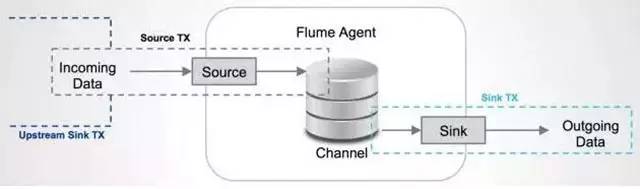
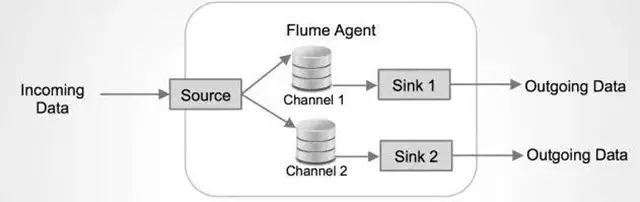
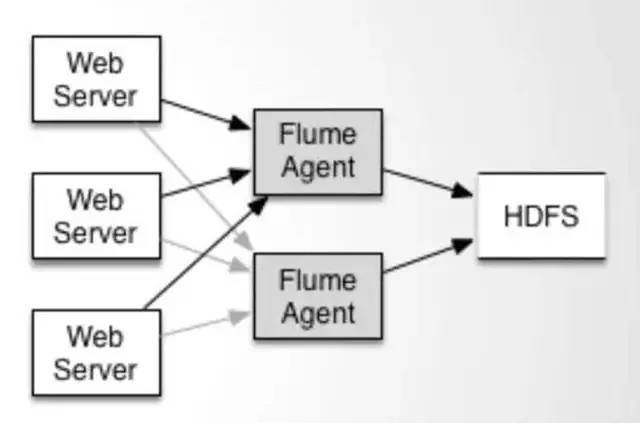
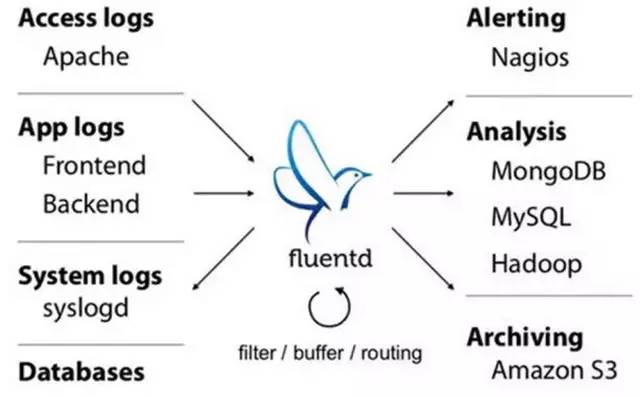
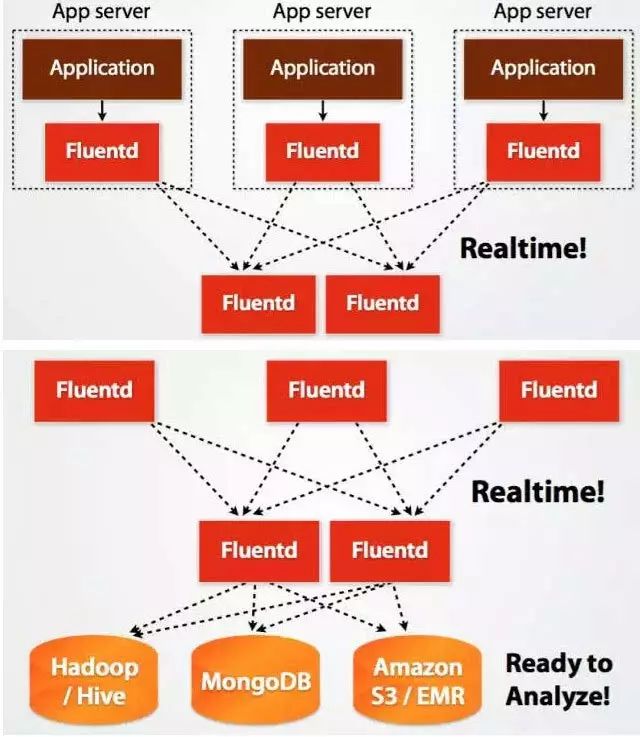
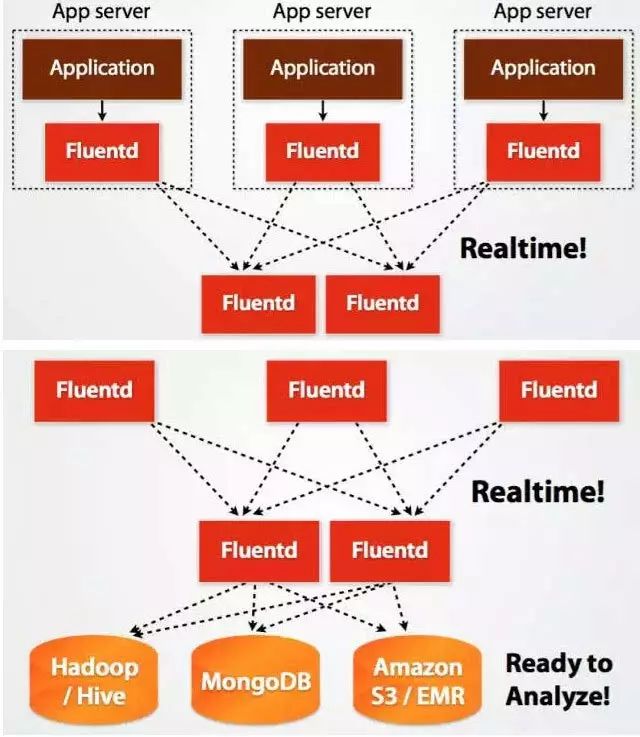
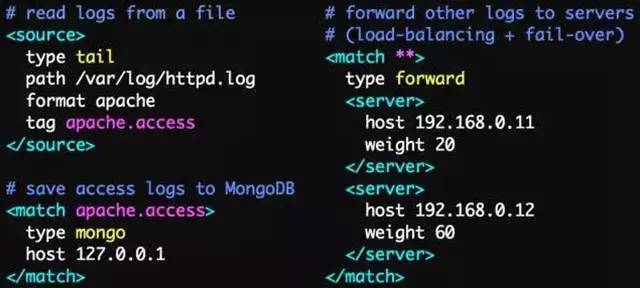
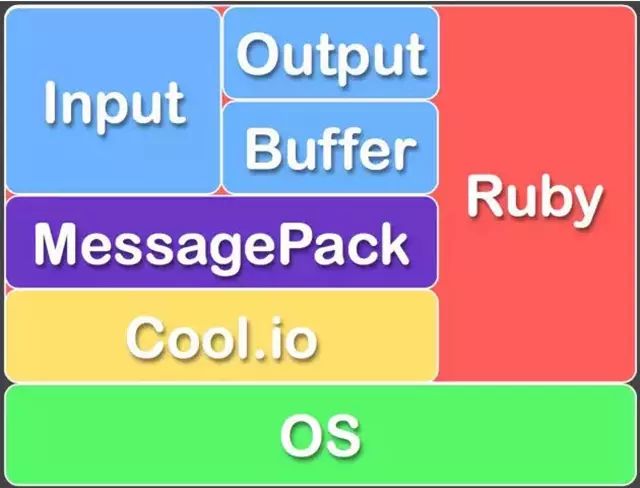
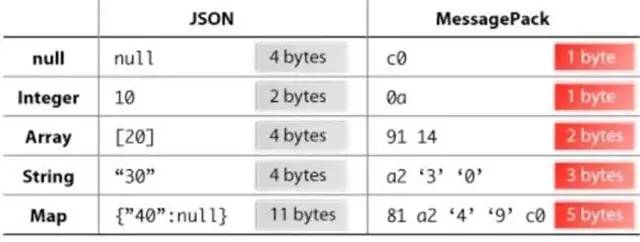
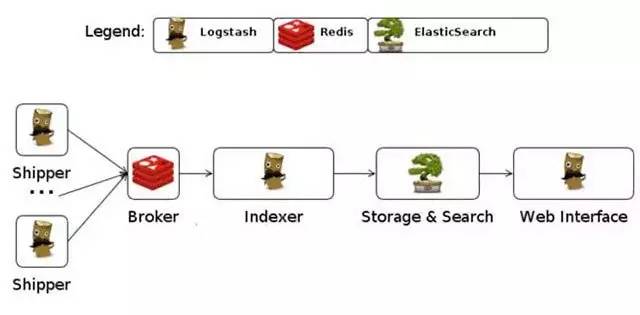
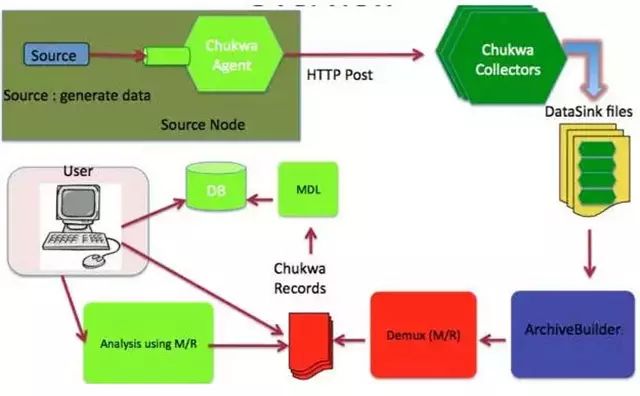
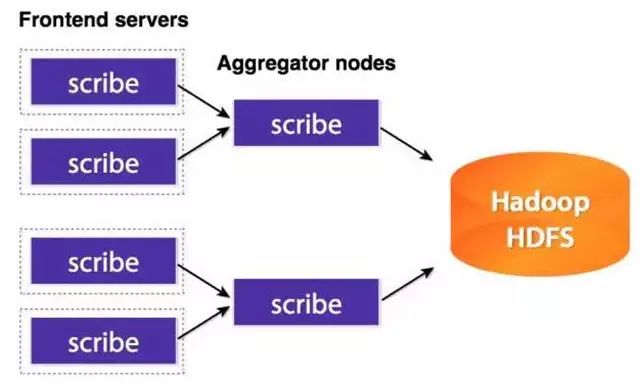
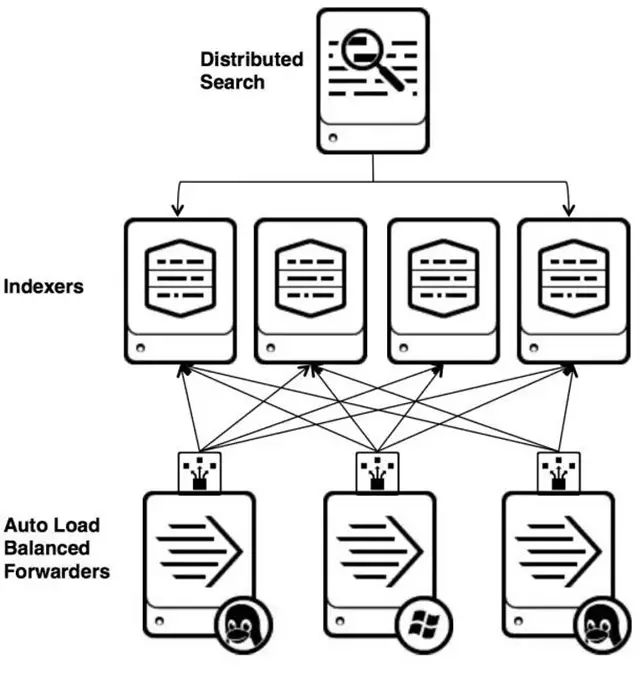
As big data becomes more and more important, the challenges of data collection become particularly acute. Today we introduce several data acquisition platforms: Apache Flume Fluentd Logstash Chukwa Scribe Splunk Forwarder. Any complete big data platform generally includes the following processes: Data Acquisition -> Data Storage -> Data Processing -> Data Presentation (Visualization, Reporting and Monitoring) Among them, data acquisition is indispensable for all data systems. With the increasing emphasis on big data, the challenges of data collection have become especially acute. This includes: Various data sources Big amount of data Change quickly How to ensure the reliability of data collection performance How to avoid duplicate data How to ensure the quality of data Let's take a look at the six data acquisition products currently available today, focusing on how they achieve high reliability, high performance, and high scalability. 1, Apache Flume Official website: https://flume.apache.org/ Flume is an open source, highly reliable, highly scalable, easily managed, and customer-extended data acquisition system under Apache. Flume builds using JRuby, so it depends on the Java runtime environment. Flume was originally designed by Cloudera's engineers to consolidate log data and was later developed to handle streaming data events. Flume is designed as a distributed pipeline architecture that can be seen as an agent network between the data source and the destination, supporting data routing. Each agent consists of Source, Channel, and Sink. Source Source is responsible for receiving input data and writing data to the pipeline. Flume's Source supports HTTP, JMS, RPC, NetCat, Exec, Spooling Directory. Spooling supports monitoring a directory or file and parsing newly generated events. Channel Channel stores cached intermediate data from source to sink. You can use different configurations for Channels, such as memory, files, JDBC, and so on. The use of high memory performance but not lasting, it is possible to lose data. Using files is more reliable but performance is not as good as memory. Sink Sink is responsible for reading data from the pipeline and sending it to the next agent or final destination. The different destination types supported by Sink include: HDFS, HBASE, Solr, ElasticSearch, File, Logger or other Flume Agents. Flume uses the transaction mechanism on both source and sink to ensure that no data is lost during data transmission. Data on Source can be copied to different channels. Each Channel can also connect a different number of Sinks. Connecting agents of different configurations in this way can form a complex data collection network. Through the configuration of the agent, a complex data transmission network can be formed. Configure the agent structure as shown in the above figure. Flume supports setting Failover and Load Balance for sinks. This ensures that even if one agent fails, the entire system can still collect data. The content transmitted in Flume is defined as an event, and the event is composed of Headers (including Meta Data) and Payload. Flume provides an SDK to support custom development: The Flume client is responsible for sending events to Flume's Agent at the source of the event. The client is usually in the same process space as the application that generated the data source. Common Flume clients are Avro, log4J, syslog, and HTTP Post. In addition, ExecSource supports specifying the output of a local process as the input to Flume. Of course, it is very likely that none of the above clients can meet the requirements. The user can customize the client, communicate with the existing FLume Source, or customize a new Source type. At the same time, users can use Flume's SDK to customize Source and Sink. Does not seem to support custom Channel. 2, Fluentd Official website: http://docs.fluentd.org/articles/quickstart Fluentd is another open source data collection framework. Fluentd uses C/Ruby development and uses JSON files to unify log data. Its pluggable architecture supports various types and formats of data sources and data output. Finally, it also provides high reliability and good scalability. Treasure Data, Inc provides support and maintenance for this product. Fluentd's deployment is very similar to Flume: Fluentd's architecture design and Flume are exactly the same: Fluentd's Input/Buffer/Output is very similar to Flume's Source/Channel/Sink. Input Input is responsible for receiving data or actively grabbing data. Support syslog, http, file tail and so on. Buffer Buffer is responsible for data acquisition performance and reliability, but also different types of Buffer file or memory can be configured. Output Output is responsible for outputting data to destinations such as files, AWS S3, or other Fluentd. Fluentd configuration is very convenient, as shown below: Fluentd's technology stack is shown below: Both FLuentd and its plugins are developed by Ruby. MessgaePack provides JSON serialization and asynchronous parallel communication RPC mechanisms. Cool.io is based on libev's event-driven framework. FLuentd's extensibility is very good, customers can customize (Ruby) Input/Buffer/Output. Fluentd is similar to Flume in all aspects. The difference is that using Ruby development, Footprint will be smaller, but it also brings cross-platform issues and does not support the Windows platform. Another use of JSON unified data / log format is another of its characteristics. Relative to the Flumed, the configuration is relatively simple. 3, Logstash Https://github.com/elastic/logstash Logstash is the L in the famous open source data stack ELK (ElasticSearch, Logstash, Kibana). Logstash was developed with JRuby and all runtimes depend on the JVM. Logstash deployment architecture as shown below, of course, this is just a deployment option. A typical Logstash configuration is as follows, including Input, Filter's Output settings. In most cases ELK is used as a stack at the same time. All logstash is preferred when your data system uses ElasticSearch. 4, Chukwa Official website: https://chukwa.apache.org/ Apache Chukwa is another open source data collection platform owned by apache. It is far from the others. Chukwa builds on Hadoop's HDFS and Map Reduce (obviously, it is implemented in Java), providing extensibility and reliability. Chukwa also provides data display, analysis and monitoring. It is strange that it was last time that github was updated 7 years ago. It can be seen that the project should have been inactive. Chukwa's deployment architecture is as follows: Chukwa's main units are: Agent, Collector, DataSink, ArchiveBuilder, Demux, etc. It looks quite complicated. Since the project is already inactive, we will not read it. 5, Scribe Code Hosting: https://github.com/facebookarchive/scribe Scribe is a data (log) collection system developed by Facebook. It has not been maintained for many years. In the same way, it will not be said. 6, Splunk Forwarder Official website: http:// All of the above systems are open source. In commercial big data platform products, Splunk provides complete data mining, data storage, data analysis and processing, and data presentation capabilities. Splunk is a distributed machine data platform with three main roles: Search Head is responsible for the search and processing of data and provides information extraction during search. Indexer is responsible for data storage and indexing Forwarder, responsible for data collection, cleaning, deformation, and sent to Indexer Splunk has built-in support for Syslog, TCP/UDP, and Spooling. At the same time, users can obtain specific data by developing Input and Modular Input. In the software warehouse provided by Splunk, there are many mature data collection applications, such as AWS, DBConnect, etc., which can easily obtain data from the cloud or database and enter Splunk's data platform for analysis. It should be noted here that both Search Head and Indexer support the configuration of the Cluster, which is highly available and highly scalable, but Splunk does not currently have the functionality of the Farwarder Cluster. This means that if there is a failure of one of Farwarder's machines, data collection will be interrupted, and it will not be possible to failover the running data acquisition task to another Farwarder. to sum up We briefly discussed several popular data collection platforms, most of which provide highly reliable and highly scalable data collection. Most platforms have abstracted the input, output, and buffer architecture of the middle. With a distributed network connection, most platforms can achieve a certain degree of scalability and high reliability. Among them, Flume and Fluentd are two more used products. If you use ElasticSearch, Logstash may be preferred because the ELK stack provides good integration. Chukwa and Scribe are not recommended due to inactive projects. As an excellent commercial product, Splunk has some limitations in its data collection. It is believed that Splunk will soon develop a better data collection solution.
Bluetooth Mini Projector
Sound can be transmitted wirelessly, no audio source cable is required.
wifi bluetooth projector,bluetooth home projector,bluetooth protable home projector Shenzhen Happybate Trading Co.,LTD , https://www.szhappybateprojectors.com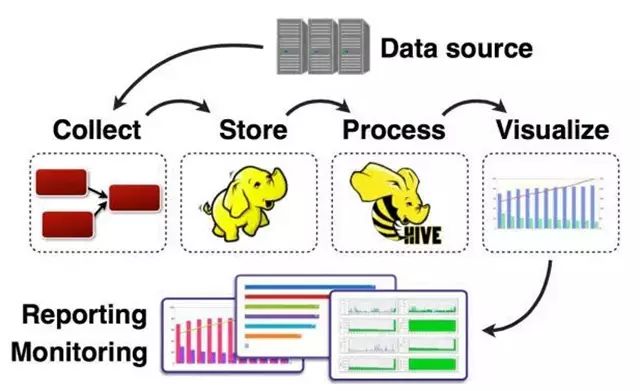



2. After the projector is connected to the mobile phone through the Bluetooth function, the projector acts as a speaker and can play music from the mobile phone.